7 minutes
Sharpe Ratio
1. Meet Professor William Sharpe
An investment may make sense if we expect it to return more money than it costs. But returns are only part of the story because they are risky - there may be a range of possible outcomes. How does one compare different investments that may deliver similar results on average, but exhibit different levels of risks?
Enter William Sharpe. He introduced the reward-to-variability ratio in 1966 that soon came to be called the Sharpe Ratio. It compares the expected returns for two investment opportunities and calculates the additional return per unit of risk an investor could obtain by choosing one over the other. In particular, it looks at the difference in returns for two investments and compares the average difference to the standard deviation (as a measure of risk) of this difference. A higher Sharpe ratio means that the reward will be higher for a given amount of risk. It is common to compare a specific opportunity against a benchmark that represents an entire category of investments.
The Sharpe ratio has been one of the most popular risk/return measures in finance, not least because it’s so simple to use. It also helped that Professor Sharpe won a Nobel Memorial Prize in Economics in 1990 for his work on the capital asset pricing model (CAPM). Let’s learn about the Sharpe ratio by calculating it for the stocks of the two tech giants Facebook and Amazon. As a benchmark, we’ll use the S&P 500 that measures the performance of the 500 largest stocks in the US.
# Importing required modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Settings to produce nice plots in a Jupyter notebook
plt.style.use('ggplot') # My preferred style choice
%matplotlib inline
# Reading in the data
stock_data = pd.read_csv("datasets/stock_data.csv", parse_dates=True, index_col=0).dropna()
benchmark_data = pd.read_csv("datasets/benchmark_data.csv", parse_dates=True, index_col=0).dropna()
2. A first glance at the data
Let’s take a look the data to find out how many observations and variables we have at our disposal.
# Display summary for stock_data
print('Stocks\n')
stock_data.info() # showing the summary of the dataframe
print(stock_data.head()) # Showing the first 5 records for the dataframe
# Display summary for benchmark_data
print('\nBenchmarks\n')
benchmark_data.info()
print(benchmark_data.head())
# Notice that the index is a DatetimeIndex
Stocks
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 252 entries, 2016-01-04 to 2016-12-30
Data columns (total 2 columns):
Amazon 252 non-null float64
Facebook 252 non-null float64
dtypes: float64(2)
memory usage: 5.9 KB
Amazon Facebook
Date
2016-01-04 636.989990 102.220001
2016-01-05 633.789978 102.730003
2016-01-06 632.650024 102.970001
2016-01-07 607.940002 97.919998
2016-01-08 607.049988 97.330002
Benchmarks
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 252 entries, 2016-01-04 to 2016-12-30
Data columns (total 1 columns):
S&P 500 252 non-null float64
dtypes: float64(1)
memory usage: 3.9 KB
S&P 500
Date
2016-01-04 2012.66
2016-01-05 2016.71
2016-01-06 1990.26
2016-01-07 1943.09
2016-01-08 1922.03
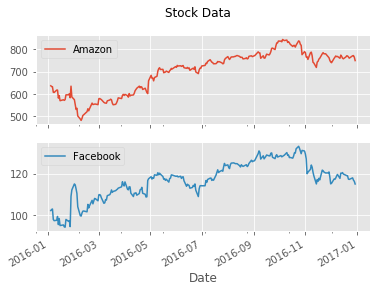
3. Plot & summarize daily prices for Amazon and Facebook
Before we compare an investment in either Facebook or Amazon with the index of the 500 largest companies in the US, let’s visualize the data, so we better understand what we’re dealing with.
# visualize the stock_data
# we set subplots to true, to show a graph for both amazon and fb
stock_data.plot(title="Stock Data", subplots=True)
# summarize the stock_data
# Because it's the last call in the cell, don't need to print()
stock_data.describe()
| Amazon | |
|---|---|
| 252.000000 | 252.000000 |
| 699.523135 | 117.035873 |
| 92.362312 | 8.899858 |
| 482.070007 | 94.160004 |
| 606.929993 | 112.202499 |
| 727.875000 | 117.765000 |
| 767.882492 | 123.902503 |
| 844.359985 | 133.279999 |
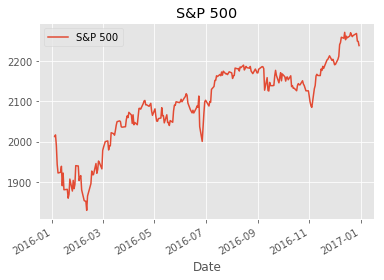
4. Visualize & summarize daily values for the S&P 500
Let’s also take a closer look at the value of the S&P 500, our benchmark.
# plot the benchmark_data
benchmark_data.plot(title="S&P 500")
# summarize the benchmark_data
benchmark_data.describe()
| S&P 500 |
|---|
| 252.000000 |
| 2094.651310 |
| 101.427615 |
| 1829.080000 |
| 2047.060000 |
| 2104.105000 |
| 2169.075000 |
| 2271.720000 |
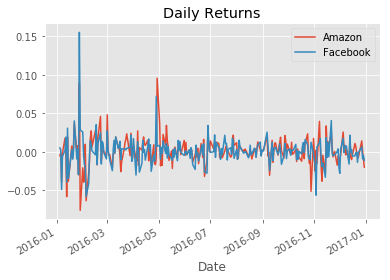
5. The inputs for the Sharpe Ratio: Starting with Daily Stock Returns
The Sharpe Ratio uses the difference in returns between the two investment opportunities under consideration. However, our data show the historical value of each investment, not the return. To calculate the return, we need to calculate the percentage change in value from one day to the next. We’ll also take a look at the summary statistics because these will become our inputs as we calculate the Sharpe Ratio. Can you already guess the result?
# calculate daily stock_data returns
stock_returns = stock_data.pct_change()
# plot the daily returns
stock_returns.plot(title="Daily Returns")
# summarize the daily returns
stock_returns.describe()
| Amazon | |
|---|---|
| 251.000000 | 251.000000 |
| 0.000818 | 0.000626 |
| 0.018383 | 0.017840 |
| -0.076100 | -0.058105 |
| -0.007211 | -0.007220 |
| 0.000857 | 0.000879 |
| 0.009224 | 0.008108 |
| 0.095664 | 0.155214 |
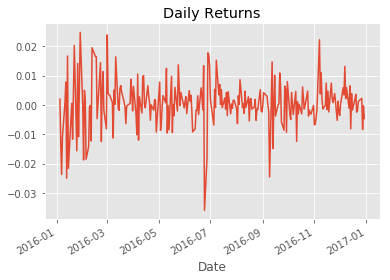
6. Daily S&P 500 returns
For the S&P 500, calculating daily returns works just the same way, we just need to make sure we select it as a Series using single brackets [] and not as a DataFrame to facilitate the calculations in the next step.
# calculate daily benchmark_data returns
bench_series = benchmark_data.iloc[:,0]
sp_returns = bench_series.pct_change()
# plot the daily returns
sp_returns.plot(title="Daily Returns")
# summarize the daily returns
sp_returns.describe()
count 251.000000
mean 0.000458
std 0.008205
min -0.035920
25% -0.002949
50% 0.000205
75% 0.004497
max 0.024760
Name: S&P 500, dtype: float64
7. Calculating Excess Returns for Amazon and Facebook vs. S&P 500
Next, we need to calculate the relative performance of stocks vs. the S&P 500 benchmark. This is calculated as the difference in returns between stock_returns and sp_returns for each day.
# calculate the difference in daily returns
excess_returns = stock_returns.sub(sp_returns, axis=0) # we set the axis to the date cols (both sets have 0 as the date)
# plot the excess_returns
excess_returns.plot(title="Excess Returns")
# summarize the excess_returns
excess_returns.describe()
| Amazon | |
|---|---|
| 251.000000 | 251.000000 |
| 0.000360 | 0.000168 |
| 0.016126 | 0.015439 |
| -0.100860 | -0.051958 |
| -0.006229 | -0.005663 |
| 0.000698 | -0.000454 |
| 0.007351 | 0.005814 |
| 0.100728 | 0.149686 |
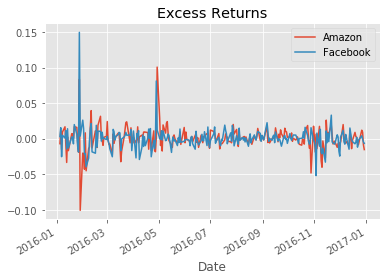
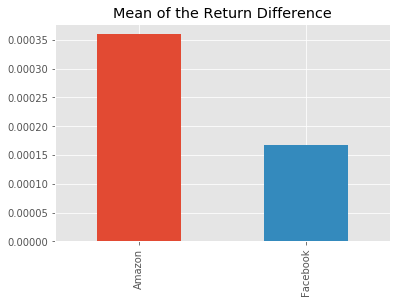
8. The Sharpe Ratio, Step 1: The Average Difference in Daily Returns Stocks vs S&P 500
Now we can finally start computing the Sharpe Ratio. First we need to calculate the average of the excess_returns. This tells us how much more or less the investment yields per day compared to the benchmark.
# calculate the mean of excess_returns
avg_excess_return = excess_returns.mean()
# plot avg_excess_returns
avg_excess_return.plot.bar(title="Mean of the Return Difference")
<matplotlib.axes._subplots.AxesSubplot at 0x1ebdf796198>
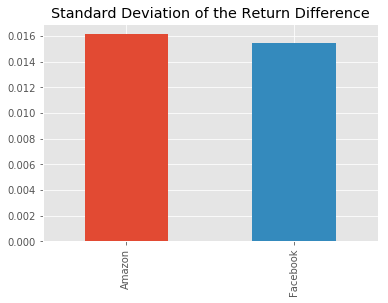
9. The Sharpe Ratio, Step 2: Standard Deviation of the Return Difference
It looks like there was quite a bit of a difference between average daily returns for Amazon and Facebook.
Next, we calculate the standard deviation of the excess_returns. This shows us the amount of risk an investment in the stocks implies as compared to an investment in the S&P 500.
# calculate the standard deviations
sd_excess_return = excess_returns.std()
# plot the standard deviations
sd_excess_return.plot.bar(title="Standard Deviation of the Return Difference")
<matplotlib.axes._subplots.AxesSubplot at 0x1ebdf6e66d8>
10. Putting it all together
Now we just need to compute the ratio of avg_excess_returns and sd_excess_returns. The result is now finally the Sharpe ratio and indicates how much more (or less) return the investment opportunity under consideration yields per unit of risk.
The Sharpe Ratio is often annualized by multiplying it by the square root of the number of periods. We have used daily data as input, so we’ll use the square root of the number of trading days (5 days, 52 weeks, minus a few holidays): √252
# calculate the daily sharpe ratio
daily_sharpe_ratio = avg_excess_return.div(sd_excess_return, axis=0)
# annualize the sharpe ratio
annual_factor = np.sqrt(252)
annual_sharpe_ratio = daily_sharpe_ratio.mul(annual_factor)
# plot the annualized sharpe ratio
annual_sharpe_ratio.plot.bar(title="Annualized Sharpe Ratio: Stocks vs S&P 500")
<matplotlib.axes._subplots.AxesSubplot at 0x2c74cf5c0f0>
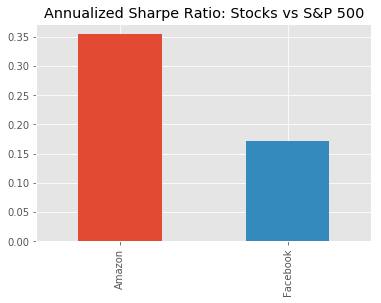
11. Conclusion
Given the two Sharpe ratios, which investment should we go for? In 2016, Amazon had a Sharpe ratio twice as high as Facebook. This means that an investment in Amazon returned twice as much compared to the S&P 500 for each unit of risk an investor would have assumed. In other words, in risk-adjusted terms, the investment in Amazon would have been more attractive. This difference was mostly driven by differences in return rather than risk between Amazon and Facebook. The risk of choosing Amazon over FB (as measured by the standard deviation) was only slightly higher so that the higher Sharpe ratio for Amazon ends up higher mainly due to the higher average daily returns for Amazon. When faced with investment alternatives that offer both different returns and risks, the Sharpe Ratio helps to make a decision by adjusting the returns by the differences in risk and allows an investor to compare investment opportunities on equal terms, that is, on an ‘apples-to-apples’ basis.
buy_amazon = True